

Anthropic's Model Context Protocol (MCP): A Universal Connector for AI
Model Context Protocol (MCP)
Large language models (LLMs) have shown remarkable prowess in understanding and generating text, but historically they’ve been isolated from the rich data and tools around them. Each time a developer wanted an AI assistant to pull information dynamically (not static training data residing in vector databases for RAG) from, say, a company wiki or a code repository, they had to write a custom connector or plugin. This approach doesn’t scale – it’s like having to craft a unique cable for every device you own.
Anthropic’s recently introduced Model Context Protocol (MCP) aims to solve this by acting as a universal connector for AI, standardizing how AI systems interface with external data and services. Think of MCP as the USB-C port for AI applications, allowing any compliant AI assistant to plug into any data source or tool in a consistent way. In this article, we’ll dive into why MCP is needed, the benefits it offers for AI integration, how it works with examples, implementation guidance, key use cases, and where it fits in the broader AI ecosystem alongside other emerging standards.
Why We Needed the Model Context Protocol
Before MCP, connecting an AI model to various external systems was an M×N problem: if you have M AI applications and N tools or data sources, you’d end up building M × N custom integrations. For example, integrating an AI agent with Slack, Google Drive, and GitHub might require three separate bespoke connectors – and doing the same for another AI system would require three more. This led to duplicated effort and inconsistent implementations across teams. Even the most advanced LLMs were “trapped behind information silos”, unable to easily access fresh data because every new connection required custom glue code. In practice, this meant AI assistants often worked with stale training data or limited context, and developers faced a huge maintenance burden to keep integrations up to date.
This fragmentation was a major barrier to scaling AI systems in the real world. Organizations found it difficult to connect powerful models to all their proprietary data and internal tools because there was no common method to do so. Additionally, without a standard, it was hard to ensure security and consistency – each custom integration might handle authentication and data access differently, potentially exposing vulnerabilities or requiring duplicate effort to enforce policies.
MCP addresses these challenges by providing a universal, open standard for connecting AI systems with data sources, replacing fragmented integrations with a single protocol. In other words, instead of writing one-off connectors for every data source, developers can build against one standard interface. This dramatically simplifies development and maintenance: an AI agent can query any MCP-compliant service and trust that the interaction follows the same rules and format as any other service.
In March 2025, OpenAI adopted rival Anthropic's standard for connecting AI models to data.
Benefits of MCP for AI System Integration and Interaction
The Model Context Protocol introduces several key benefits that fundamentally improve how AI systems integrate and interact with external resources:
- Standardization and Interoperability: MCP defines a common language (based on JSON-RPC 2.0) for AI <-> tool communication. This means an AI model interacting with a file system or a Slack channel does so in a standardized way. By replacing many bespoke APIs with one protocol, MCP makes integrations more reliable and easier to develop. It also promotes interoperability: any AI client that speaks MCP can talk to any MCP server, regardless of programming language or vendor.
- AI-Native Design: Unlike older integration standards (e.g. REST, OpenAPI) that are generic, MCP was designed for modern AI agents from the ground up. It formalizes patterns like tools (actions the AI can invoke), resources (contextual data the AI can read), and prompts (predefined query templates) – concepts that align with how we build AI-driven applications. This AI-centric design means MCP naturally handles things like tool discovery, calling, and context injection in ways that fit an LLM’s workflow.
- Unified Context and Memory Across Platforms: As the ecosystem of MCP integrations grows, an AI system can carry its context across different tools and datasets more gracefully. For example, an AI agent could retrieve a document via a Google Drive MCP server, then switch to a database MCP server to fetch related data, all while maintaining the conversation context. In the future, AI assistants will maintain context as they move between tools, replacing today’s fragmented “one-off” plugins with a cohesive, sustainable architecture.
- Efficiency and Reusability: MCP turns integrations into reusable building blocks. A single well-built MCP server for, say, GitHub can be used by any number of AI applications (IDEs, chatbots, agents) to interact with GitHub. This fosters a community of shareable connectors. In fact, Anthropic kickstarted MCP with an open-source repository of servers for popular systems like Google Drive, Slack, Git, GitHub, Postgres, and even web browsers (via Puppeteer). Instead of each company writing their own Slack-bot code, they can all leverage the standard Slack MCP server (or customize it if needed) and immediately be up and running. This reusability accelerates development of new AI features since developers can focus on higher-level logic rather than low-level API wrangling.
- Multi-Platform and Vendor Neutral: MCP is model-agnostic and vendor-neutral – it’s an open protocol not tied to Claude or any single provider. This means you could use MCP to connect a GPT-4 model to tools just as well as you could connect Anthropic’s Claude or another LLM. In practice, we’re seeing broad adoption: Microsoft has integrated MCP into Azure OpenAI to let GPT models fetch live data, and OpenAI itself announced support for MCP across its products (including the ChatGPT desktop app and its Agents SDK). Such cross-industry support positions MCP as a potential de facto standard for tool-using AI agents.
- Secure Two-Way Connectivity: MCP was built with a secure, two-way connection model in mind. Developers can expose data through MCP servers on their own infrastructure, keeping sensitive data behind their firewall, while AI clients connect in a controlled manner. The protocol encourages a “human in the loop” for actions – tools (which can change state) are model-invoked but typically require user approval to execute. Meanwhile, the client (running in the host app) can sandbox each server connection, enforcing access controls. Overall, MCP provides best practices for integrating AI with enterprise data securely, which is crucial for real-world deployments.
- Rich Interaction Patterns (Beyond Simple API Calls): Because MCP uses a persistent JSON-RPC connection, it supports continuous interactions and streaming updates, not just single request-responses. For instance, an MCP server can send notifications when a resource’s content updates or when new resources become available (think of a server notifying the AI about a newly arrived email). This event-driven capability allows AI assistants to handle real-time information. Traditional function calling or API use is typically one-shot – ask and get an answer – whereas MCP can maintain a live link to external data.
- Built on Proven Foundations: MCP didn’t reinvent the wheel where it didn’t need to. It draws inspiration from Microsoft’s Language Server Protocol (LSP) – which unified how code editors interact with programming language tools – and similarly aims to unify AI tool interactions. It leverages JSON-RPC 2.0, a well-established standard for structured communication, meaning the protocol messages are human-readable JSON and there are many libraries and best practices to rely on. Using these foundations, MCP ensures a low barrier to implementation and robust communication patterns (e.g. support for notifications, asynchronous calls, etc.).
MCP Architecture and Components
At its core, MCP follows a client–server architecture that cleanly separates AI applications from the external tools/data they use. Let’s break down the key components in an MCP setup:
- Host Process (or Host Application): This is the parent application or environment where the AI assistant lives – essentially the place where the user interacts with the AI. Examples of hosts include the Claude desktop app, a chat interface, an IDE like VS Code or Zed with an AI coding assistant, or a custom agent runtime. The host is responsible for managing connections to one or more MCP servers on behalf of the AI. It’s also where the LLM model actually runs or is accessed (the host might call out to an AI API like Claude or GPT-4). The host coordinates between the user, the LLM, and any MCP servers.
- MCP Client: The MCP client is the component (often a library or part of the host) that handles the communication to a specific MCP server. Each server connection uses one client instance – meaning if the host needs to connect to a GitHub server and a Slack server, it will spawn two MCP clients. The client speaks the MCP protocol (JSON-RPC messages) and takes care of low-level details like establishing the connection, sending requests (e.g. “give me list of files”), and receiving responses or events. By design, the MCP client can enforce security and sandboxing. Because it’s managed by the host, the host has fine-grained control: it can decide which servers to spin up, when to shut them down, and how to route the AI’s requests through them. The client is essentially the adapter or driver within the host that knows how to talk MCP.
- MCP Server: An MCP server is a lightweight program that implements the MCP standard to expose some set of capabilities or data. Think of it as a translator or wrapper around an external system. For example, a Google Drive MCP server might handle commands to list files, read file contents, or search documents; under the hood it calls Google’s API, but to an AI client it presents a uniform MCP interface. Similarly, a database MCP server could accept a query from the AI (via the client) and then run it on an actual database, returning results. Servers can interface with anything: local file systems, cloud services, internal APIs, developer tools, etc. They advertise what they can do in terms of standardized primitives: “resources” they can provide, “tools” they can execute, and “prompts” they supply (more on these shortly). Importantly, servers are external to the AI model – they don’t require changes to the model itself, and they can be implemented in any language as long as they follow the protocol. Anthropic provides SDKs in multiple languages (TypeScript, Python, Java, Kotlin, C#) to make it easier to build MCP servers (and clients) (Model Context Protocol · GitHub).
These three pieces work together like this: the Host (with an LLM) uses an MCP Client to send requests to an MCP Server, and the server fulfills those requests using the external tool or data source it represents. The communication is typically asynchronous JSON messages, which allows for a back-and-forth dialogue (e.g., the client can request something, the server responds, or the server can send notifications/events).
A helpful way to visualize it: the host and server are like two ends of a conversation, and the MCP client is the phone line between them ensuring they speak the same language. The host might say “Hey, GitHub server, what files do we have in repo X related to Y?” and the server will answer with the data.
Tools, Resources, and Prompts: MCP standardizes three types of capabilities that a server can provide:
- Tools – “Model-controlled” actions. Tools are operations that the AI can ask the server to perform, analogous to functions the AI can call. These could be anything from “search the company wiki for X” to “send an email” or “execute this code.” Each tool has a name, description, and a JSON schema for its input parameters (and sometimes output schema). Tools generally perform deterministic operations. For instance, a weather tool might call a weather API and return the result, or a database write tool might insert a record. In MCP, tools are intended to be invoked by the AI (with user approval as needed) – they expand what the model can do by letting it act through the server. The protocol defines endpoints like
tools/list(to discover available tools on a server) andtools/call(to invoke a tool). This concept parallels “function calling” in OpenAI’s API, but in MCP it’s part of a broader framework (we’ll compare later). - Resources – “Application-controlled” data. Resources are pieces of data or content that the server exposes for the AI to use as read-only context. For example, a filesystem server might expose a text file as a resource, or an email server might expose the body of an email. Resources do not typically involve heavy computation or side effects – they’re more like fetching information (similar to GET requests in a REST API). Each resource is identified by a URI (like
file:///path/to/file.txtordb://employees/123). The AI (via the client) can list available resources (resources/list) and read them (resources/read) to get the content. Resources essentially are how an MCP server says “here are chunks of data you might want.” The host or user often decides which resources to actually pull in (to avoid information overload or irrelevance). By structuring data as resources, MCP gives the AI knowledge (beyond its base training) in a controlled way. - Prompts – “User-controlled” templates. Prompts in MCP are predefined prompt templates or workflow scripts that the server can provide to help orchestrate complex interactions. These are meant to be surfaced to the user or host, who can choose to apply them. For example, a server might have a prompt called “Document Q&A” that, when invoked, guides the AI to use that server’s resources to answer questions about a document. Prompts can accept arguments and can even chain multiple steps (they might specify a sequence of tool calls or resource fetches). Essentially, prompts are reusable recipes for the AI, provided by the server, to make it easy to perform common tasks. An IDE integration might have a prompt like “Review this code for bugs” which under the hood might cause the AI to use a linter tool and fetch relevant documentation. MCP clients can query
prompts/listto see what prompts a server offers. Prompts help with standardizing complex interactions so that users (or AI) don’t have to reinvent them each time.
These three primitives work in concert. For example, an MCP server for a knowledge base might expose a resource for each knowledge article, a tool to search the knowledge base, and a prompt template for asking questions about a selected article (which ensures the AI uses the resource and maybe some tools in a structured way). By standardizing these, MCP makes it clear how an AI can discover “what can I do?” when connected to a new server (list tools, list resources, list prompts) and then how to execute actions or gather context.
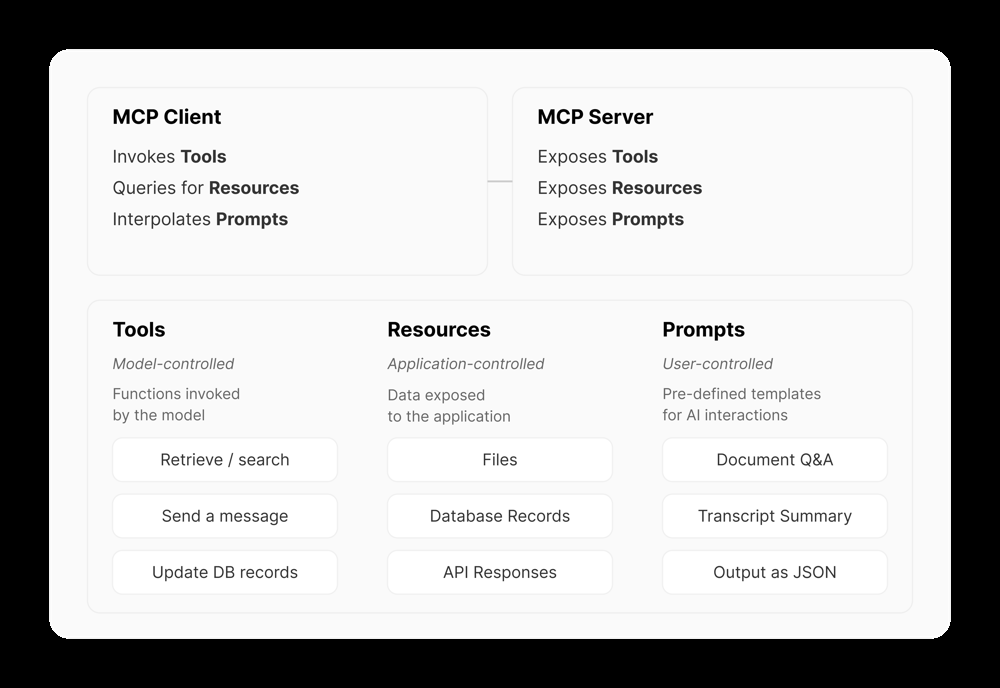
Overview of MCP components : The MCP Server exposes Tools, Resources, and Prompts. The MCP Client (in the host application) connects to the server, invokes tools on behalf of the model, fetches resources, and provides prompt templates to the user/LLM. Tools are model-controlled functions (e.g. search, send message), Resources are application-controlled data (files, database records, etc.), and Prompts are user-controlled templates (like “Document Q&A”).
Communication and Transports: MCP communication is typically over a persistent connection. It supports multiple transports depending on deployment: for local servers, a simple stdio pipe can be used. For remote servers, MCP can work over HTTP with Server-Sent Events (SSE) for streaming, and even WebSockets in the future or via community extensions. The important thing is that no matter the transport, the message format remains JSON-RPC. A typical message might look like:
1// Example JSON-RPC request from client to server to list available tools 2{ "jsonrpc": "2.0", "id": 1, "method": "tools/list", "params": {} }
And the corresponding response from the server might be:
1{ 2 "jsonrpc": "2.0", 3 "id": 1, 4 "result": { 5 "tools": [ 6 { 7 "name": "add", 8 "description": "Add two numbers", 9 "inputSchema": { 10 "type": "object", 11 "properties": { 12 "a": { "type": "number" }, 13 "b": { "type": "number" } 14 } 15 } 16 } 17 // ... potentially other tools ... 18 ] 19 } 20}
In this hypothetical snippet, the server lists a tool named “add”. If the AI decided to use this tool, the client would send a tools/call request like:
1{ 2 "jsonrpc": "2.0", 3 "id": 2, 4 "method": "tools/call", 5 "params": { "tool": "add", "arguments": { "a": 5, "b": 3 } } 6}
And the server’s result would contain the outcome of that operation:
1{ "jsonrpc": "2.0", "id": 2, "result": 8 }
Notice how the protocol itself doesn’t prescribe what “add” does – that’s up to the server – but it standardizes how it’s invoked and returned (including using JSON Schema for inputs). This JSON-based exchange is what makes MCP universal: any client and any server adhering to it can work together.
What MCP Looks Like in Action
Let’s walk through a concrete example to see MCP in action. Imagine we have an AI coding assistant integrated into an IDE (the host). We want this assistant to be able to fetch relevant code snippets from a GitHub repository and also get information from a project management tool (say Jira) to inform its answers. Without MCP, we’d have to program the assistant with GitHub API calls and Jira API calls manually. With MCP, we can run a GitHub MCP server and a Jira MCP server, and let the assistant leverage both easily.
1. Initialization: When the AI assistant (in the IDE) starts up, the host spawns two MCP client connections – one for the GitHub server, one for the Jira server. Each client and server perform a handshake to establish protocol version and capabilities. Under the hood, the client sends an initialize request and the server responds with its name, version, and supported features (tools, resources, prompts etc.). This step ensures both sides agree on how to communicate going forward.
2. Discovery of Capabilities: Once connected, the IDE’s MCP clients query each server for what it offers:
- For GitHub server, the client calls
tools/list,resources/list,prompts/list. Suppose the GitHub server responds that it has tools likesearch_codeandopen_issue, resources likerepo://...files, and prompts like “Find relevant code snippet”. - The Jira server might list tools such as
search_ticketsand resources for recent tickets, etc.
The host now knows what each server can do. It could present some of this to the user (for example, showing a list of data sources available or enabling UI commands), and it will also internally prepare the LLM to use these tools. For instance, the host can take the tool definitions and supply them to the LLM as available functions (if the LLM supports function calling natively).
3. Context Provisioning: When the user asks the AI a question – say, “How can I improve the function that handles user login?” – the AI (LLM) processes the query. Recognizing it might need external info, the host can proactively fetch some context. For example, it might use the GitHub server’s resources: find the file defining the login function and provide it to the model as context. Or it could surface a Prompt provided by the server, like a “Code Analysis” prompt that guides the AI to examine code. This step is about giving the model the relevant background before or as it forms a response. MCP makes this easy by letting the host quickly grab whatever data is needed (via resources/read etc.) from any connected source.
4. Tool Invocation by the AI: As the model forms its response, it might determine it should take an action. Let’s say the model thinks: “I should search the repository for where the login function is called.” Using the function-calling interface, the model “calls” the search_code tool with the query “login function usage”. The host receives this function call (since the host provided the tool info to the model earlier), and now translates it into an MCP request to the GitHub server. Specifically, the host’s MCP client sends a tools/call to the GitHub server with { tool: "search_code", arguments: {"query": "login function"} }.
5. Execution on the Server: The GitHub MCP server, upon receiving the search_code request, executes its logic – perhaps calling GitHub’s API or searching a local clone of the repo – and gathers results (say it finds two files where the login function is referenced). The server then returns a result via JSON-RPC, e.g., a JSON object containing the filenames and a brief excerpt of each find.
6. Response and Integration: The MCP client receives this result and hands it back to the host/LLM. The host inserts the tool’s result into the conversation context for the LLM (often this is done by adding a hidden assistant message like: “Tool output: [the search results]” or directly via the function calling mechanism). Now the LLM has the information it requested and can continue formulating its answer to the user. It might incorporate the search results, or decide it needs another tool call (it could loop – e.g. open one of the files to read content, which would be another resources/read or tools/call to fetch that file’s content).
7. Final Answer: Eventually, armed with all the external info (code references, maybe Jira ticket details if it fetched those too), the LLM crafts a solution and responds to the user: “The login function could be improved by X. I found where it’s used in auth.js and userService.js, so changes there might be needed as well.” The user receives a comprehensive answer that was possible because the AI could dynamically pull in knowledge from GitHub and Jira in real-time, orchestrated through MCP.
This flow demonstrates how MCP enables interactive, tool-using behavior in AI systems in a structured way. The AI didn’t need to have all that knowledge upfront, nor did the developers have to custom-code the search behavior into the AI. Instead, by plugging into MCP servers, the AI could autonomously decide to use available tools to fetch what it needed. All the while, the host application remained in control: it chose what servers to connect, it could approve or veto tool calls, and it managed feeding the results back to the model.
To illustrate this with code, here’s a tiny snippet using the Python MCP SDK showing how an AI application might connect to a local MCP server and invoke a tool:
1from mcp import ClientSession, StdioServerParameters 2from mcp.client.stdio import stdio_client 3 4# Start an MCP server process (for example, a simple calculator server) 5server_params = StdioServerParameters(command="python", args=["calc_server.py"]) 6async with stdio_client(server_params) as (read, write): 7 async with ClientSession(read, write) as session: 8 await session.initialize() # handshake with server 9 tools = await session.list_tools() # discover tools 10 print([t.name for t in tools.tools]) # e.g. ["add", "subtract"] 11 12 result = await session.call_tool("add", arguments={"a": 5, "b": 3}) 13 print(result.output) # expect output: 8
In this pseudo-code, calc_server.py would be an MCP server that defines an “add” tool. The client session finds the tool and calls it, retrieving the sum. This example is simplistic, but in a real scenario the pattern extends to more complex tools and multiple servers. The key point is that the AI application developer doesn’t have to worry about *how* the add function works or where it runs – they just call session.call_tool("add", ...) and MCP does the rest (via JSON-RPC under the hood). Similarly, if the app needed to read a resource, it would call session.read_resource(uri) and get back the content.

How to Implement MCP (Technical and Conceptual Steps)
Implementing MCP in your projects involves two sides: building or deploying MCP servers for the tools/data you want to expose, and integrating an MCP client into your AI application (the host). Let’s break down the steps for each:
A. Implementing an MCP Server (for Tool/Data Providers):
-
Decide on Capabilities: First, identify what functionality or data your server will expose. Will it provide Tools (actions) for the AI to perform? Resources (data) for the AI to read? Prompts (templates) to guide usage? For example, if making a weather server, you might offer a tool
get_forecast(location)and a prompt “Weather report format”, but probably no long-lived resources. If making a file server, you’ll mostly provide resources (file contents) and maybe a tool to search files. -
Use an MCP SDK or Framework: Anthropic’s MCP comes with SDKs in multiple languages (TypeScript, Python, Java, Kotlin, C#) (Model Context Protocol · GitHub). These SDKs abstract a lot of the JSON-RPC handling and let you define tools/resources in a more natural way. For instance, the Python SDK might allow a decorator-based approach. Using the earlier code example with a hypothetical Python SDK called
FastMCP:1from fastmcp import FastMCP 2 3mcp = FastMCP(server_name="Demo Server") 4 5@mcp.tool() 6def add(a: int, b: int) -> int: 7 """Add two numbers""" 8 return a + b 9 10@mcp.resource("greeting://{name}") 11def get_greeting(name: str) -> str: 12 """A simple resource that greets by name""" 13 return f"Hello, {name}!"In this snippet, decorating a function with
@mcp.tool()automatically registers it as a Tool (with name “add”, description from the docstring, and input schema derived from type hints). The@mcp.resource("greeting://{name}")registers a Resource template; any URI likegreeting://Alicewill callget_greeting("Alice"). When you run this server, the SDK handles the MCP protocol – listing the tools and resources, acceptingtools/callorresources/readrequests, etc., using your Python functions to fulfill them. Essentially, the SDK turns your functions into MCP endpoints. -
Implement Handlers for Required Endpoints: If not using an SDK (or even if you are), ensure your server can respond to the core MCP methods:
initialize(the handshake),tools/list,tools/call(if you have tools),resources/listandresources/read(if resources),prompts/list(if prompts),- and potentially handle subscription endpoints if you want to push updates (
resources/subscribe, etc.).
The good news: the SDKs typically handle a lot of this boilerplate. For example, in TypeScript SDK, you might do something like
server.setRequestHandler(ListResourcesRequestSchema, ...)to define what happens on aresources/listcall (Resources - Model Context Protocol) List available resources server). -
Security & Permissions: Build in any necessary security checks. MCP itself doesn’t enforce auth (it assumes the host and server have been connected in a trusted context), but if your server connects to a sensitive system, make sure to require credentials or run it in an environment where only authorized hosts can access it. Also consider adding logic if needed to limit what data is exposed. For example, a file server might restrict certain directories.
-
Testing with an MCP Client: Once your server is running, test it using a client – Anthropic provides a GUI tool called MCP Inspector for testing, and you can also use a simple script to verify that listing and calling works as expected. This ensures your server complies with the spec.
-
Deployment: Decide how your server will run. It could be a local process launched on-demand (like some IDEs might auto-start a local MCP server for Git when needed), or a persistent service (for example, a cloud server exposing a company database via MCP). MCP servers are typically lightweight; they can be spun up quickly. Some might be packaged as single binaries or scripts so that end-users (or devops) can easily deploy them.
B. Implementing MCP Client Integration (for AI Application Developers):
-
Choose the Client Strategy: If you are building an AI application (like a chatbot, IDE plugin, or agent), check if your platform already has MCP support. If you’re rolling your own, you can use the MCP SDKs on the client side as well. The TypeScript or Python SDK can act as a client library in addition to server library. Evaluate if you need the client to spawn servers (via stdio) or connect over network.
-
Connection Setup: Establish connections to relevant servers when your app starts or when needed. You might have a config that lists what MCP servers to connect (e.g., a list of server executables or endpoints). Using SDK, it might be as simple as providing a command or URL. For example, using Python:
1server_params = StdioServerParameters(command="my_server_executable") 2session = await ClientSession.connect(server_params) 3await session.initialize()This would launch the server and perform the handshake. If connecting to a remote server with SSE, you’d use an HTTP URL instead in the parameters.
-
Discover and Register Capabilities: After initializing, call
list_tools(),list_resources(),list_prompts()on the session (or the equivalent in your library) to get what the server offers. Depending on your AI model, you need to make these capabilities known to it:- For Tools: If your model supports function calling (like OpenAI’s models or others), you’d convert each MCP tool into the model’s function schema format (name, description, JSON parameters). Many libraries can help with this mapping. In the example of a Google Gemini model, one would take the list of MCP tools and supply them to the model’s API call as allowable functions.
- For Resources: You might not directly tell the model about all resources upfront. Instead, you might use some strategy to bring in resource content when relevant. Some applications let the user pick which resources to include. Alternatively, an agent might decide to read a resource when needed, so the model might have a tool (function) to fetch a resource by URI.
- For Prompts: You can surface these as UI options (like a dropdown of special commands the user can invoke), or if your agent is autonomous, it might choose a prompt template and fill it in.
-
Integration with the LLM Loop: The core logic of your application likely revolves around taking user input, sending it to the LLM (with some context), and returning the LLM’s answer. With MCP in the mix, your loop now also handles tool calls:
- Provide the LLM with the available functions (tools) before generating a completion.
- After getting the LLM’s output, check if it requested any function/tool to be called.
- If yes, pause the model’s reply, execute
session.call_tool()for each function call (there could be multiple in sequence). - Get the result(s) and inject them back to the model as context (often as the assistant’s function result message in function calling paradigm).
- Continue the conversation by asking the model for the next part of its answer with the new info included.
- Loop this until the model has finished answering without calling further tools (or you hit some safety limit on loops).
This orchestration can be complex, but thankfully frameworks exist (OpenAI’s function calling handling, GPT-trainer's multi-agent framework, or libraries like LangChain and LlamaIndex) which can manage the loop. But with MCP, a lot of the boilerplate (discovering and calling tools uniformly) is handled, so your focus is on managing the sequence of calls and responses logically.
-
User Interface & Control: If this is a user-facing app, integrate MCP-related info into your UI. For example, show the user which data sources are connected via MCP. Perhaps allow them to enable/disable some or approve actions. E.g., if the AI wants to send an email (a tool call on an email server), you may prompt the user “The AI wants to use the email tool, allow? [Y/N]”. This keeps a human in the loop for sensitive operations. Also consider letting users add new MCP server connections via settings (since one big advantage is extensibility – today they want Slack, tomorrow maybe they plug in a new “Calendar” MCP server).
-
Error Handling and Fallbacks: Plan for cases where a server might be slow or unavailable. Your client should handle timeouts or errors from the MCP server gracefully – perhaps telling the model that the tool failed, so it can apologize or try a different strategy. Also, if the model asks for a tool that isn’t available, the client should respond appropriately (usually the model shouldn’t if you gave it the right list, but it might hallucinate a tool name; you might need to handle a “method not found” error from the server by informing the model that capability isn’t there).
Conceptually, always remember: the server is an adapter exposing an external capability, and the client is your bridge from the AI to that adapter. If you stick to the protocol and use the provided libraries, you don’t need to worry about the low-level details of message passing or compatibility.
It’s also worth noting that you don’t always have to build from scratch. Many pre-built MCP servers exist (from Anthropic’s official connectors and a growing community repository), so often it’s a matter of deploying one and writing just the client integration. For instance, to give an AI access to Slack, you might just run the open-source Slack MCP server and then configure your app to connect to it – no custom Slack API code required on your side.
Use Cases and Who Benefits from MCP
The introduction of MCP unlocks a wide range of use cases by making it easier to tie AI into the tools and data people care about. Here are some of the most direct beneficiaries:
- AI Agents and Autonomous Assistants: Developers building multi-step AI agents (systems that plan and execute tasks) benefit hugely from MCP. Such agents often need to use multiple tools in sequence – e.g., browse the web, then call an API, then save a file. MCP gives a clear structure to do this. Instead of writing custom code for each tool, the agent can rely on MCP to interface with any new tool it encounters. Early adopters like Block (formerly Square) have emphasized how an open protocol like MCP enables “agentic systems, which remove the burden of the mechanical so people can focus on the creative”. In practice, an autonomous research agent could plug into a suite of MCP servers (for web search, for data analysis in Python, for interfacing with a database) and accomplish complex goals by chaining tool calls – all standardized.
- IDE Plugins and Coding Assistants: This is a hot area – AI pair programmers that can not only suggest code, but also read your codebase, run it, test it, and debug it. Companies like Sourcegraph, Replit, Zed, and Codeium have been working with MCP to enhance their developer platforms. Using MCP, an IDE assistant can fetch code from across your repository (via a Git MCP server), perform git operations, query documentation or issue trackers, etc. For example, a Codeium plugin might use a GitLab MCP server to let the AI open merge requests or find relevant commit messages to explain a piece of code. Developers benefit from an AI that truly understands the context of their project (because it can access all project data through MCP) and can take actions (like creating a branch or running tests via tools). The fact that all these IDEs are converging on MCP means down the line, they could share connectors – a Unity Engine MCP server built for one game IDE could be reused in another, for instance.
- Office Productivity and Collaboration Tools: Think AI assistants in Slack, Teams, Notion, or other workspace apps. MCP provides a uniform way for an AI to interface with messaging data, calendars, documents, etc. There are already servers for Slack and Google Drive; one can imagine MCP servers for Outlook/Exchange, Notion, or Google Calendar if not already available. A collaborative meeting assistant could connect to a Calendar MCP server to get meeting info, a Document MCP server to fetch the agenda, and a Transcription MCP server to record the meeting – orchestrating all via one model. Enterprise users especially benefit here: rather than using a bunch of separate AI bots for each app, a single AI assistant (like a GPT-trainer chatbot in an enterprise setting) could span across systems by using MCP to fetch relevant context on the fly. This is powerful for answering questions like “Summarize the recent customer issues discussed on Slack and link any related Jira tickets” – something that touches multiple systems.
- Retrieval-Augmented Generation (RAG) Systems: RAG is about supplying documents or data to an LLM to ground its answers (typical QA over a knowledge base). MCP shines here by offering a flexible way to retrieve documents. Instead of a tightly coupled RAG pipeline, you could have an MCP server for your knowledge base (for example, one that vector-searches documents) exposing a search tool and document resources. The AI can decide when to call the search tool and then read the docs returned. This moves retrieval into a standardized, controllable layer. It’s beneficial for anyone building chatbots over proprietary data – they can leverage open MCP connectors for common storage systems (SQL databases, cloud storage, etc.) to fetch data. And because MCP is realtime, the chatbot can always get the latest info, not just a fixed snapshot.
- Data Analysis and Business Intelligence: An AI analyst could use MCP to interface with databases (there is a Postgres read-only MCP server already, and others for SQL/NoSQL likely exist) and analytics tools. For instance, a finance chatbot could query a database of sales using a
query_salestool or directly reading a resource likepostgres://fin_db/quarterly_reports. Likewise, it could use a spreadsheet MCP server to operate on Excel/Google Sheets. Traditionally, BI chatbots have custom integrations for each data source; MCP could replace those with a uniform approach. Companies are interested in this to allow non-technical users to ask natural language questions and the AI behind the scenes draws from various data systems seamlessly. - Personal Assistants and Automation: On the individual level, a power user could set up an AI agent that uses MCP to manage their personal data – emails, to-do list, smart home devices, etc. For example, a hobbyist could run an MCP server that wraps their smart home API (exposing tools like
turn_on_lightor resources likethermostat://living_room). Then their favorite AI model (through an MCP-enabled app) could control those by voice commands. We’re essentially talking about the agentic AI everyone imagines, but MCP provides the standard plug for all these systems. Early community projects have popped up exposing everything from Docker to web browsers to even Minecraft servers through MCP, showing the creative range of applications.
Ultimately, developers and organizations who want to integrate AI capabilities into existing systems stand to gain the most. Instead of waiting for AI vendors to support a specific integration or building it all in-house, they can tap into the growing MCP ecosystem. As noted, companies like Block and Apollo have already integrated MCP internally, and many others in different domains (finance, dev tools, SaaS apps) are embracing it because it accelerates connecting AI with their products.
Even end-users benefit indirectly: as MCP makes it easier to add AI features to software, we’ll see smarter applications across the board – from customer support tools that can look up order info, to medical assistants that can pull patient data (with proper compliance), all via a common, audited protocol rather than opaque custom code.

The Future of MCP in the AI Ecosystem
MCP is rapidly emerging as a central piece in the puzzle of AI integration. Its timing and design have positioned it amid several other efforts to extend AI model capabilities, so it’s worth looking at how it fits in:
MCP vs. OpenAI’s Function Calling: OpenAI’s function calling (introduced mid-2023) lets developers define functions that an LLM can call during a conversation. It’s a powerful feature that made tool use easier, but it’s essentially API-specific – each provider (OpenAI, Cohere, etc.) could have their own flavor. MCP complements function calling by standardizing the layer beneath it. Instead of hardcoding a set of functions for a particular model, MCP lets you dynamically fetch what functions (tools) are available from an external server. It then manages invoking them through a structured protocol. Think of function calling as giving the model a way to speak to external functions, and MCP as actually hooking up a whole catalog of external functions and data in a consistent way. Another distinction: function calling is typically one-turn (model decides and the developer executes the function), whereas MCP can maintain a persistent, multi-turn interaction (with ongoing data streams, updates, etc.). Function calling is also vendor-specific and not standardized across the industry. MCP is solving that problem by being model-agnostic and openly governed. One can use OpenAI’s function calling and MCP together: the model triggers a function, which internally maps to an MCP tool call. This synergy was demonstrated with Google’s Gemini model working alongside an MCP server. In short, function calling is a feature; MCP is the protocol that can leverage that feature across any model, making tool use scalable and interoperable.
MCP vs. Microsoft’s Semantic Kernel: Microsoft’s Semantic Kernel (SK) is an SDK for creating complex AI applications, particularly focusing on orchestration of “skills” (code functions the AI can call), memory, and planning. SK provides a framework – for example, you can define plugins/skills for an AI (like an email skill) in C# or Python, and SK helps manage prompting the model and routing to skills. In a sense, SK and LangChain (discussed next) solve similar problems as MCP but at a different layer. They provide patterns for connecting AI to tools, but historically each SK skill or LangChain tool was still a custom integration under the hood. MCP could serve as a unifying backend for such frameworks. In fact, Microsoft has integrated MCP support into Azure OpenAI and related tooling, which suggests Semantic Kernel could leverage MCP servers as skill endpoints. Where SK might have had a custom implementation for, say, a Jira connector, it could instead use a standard MCP Jira server and focus more on how to use it (planning, etc.). The big difference is standard vs. framework: MCP standardizes the interface, while Semantic Kernel helps manage AI workflows. One doesn’t obviate the other – they can be complementary. The future might see SK (and similar orchestrators) adopt MCP as the default way to plug in new skills, simplifying the developer’s job.
MCP vs. LangChain Interface Patterns: LangChain became popular for enabling “agents” that use tools. In LangChain, you define a set of Tool objects (each with a name, description, and a function to execute in code), then LangChain’s agent logic will let an LLM choose to call those tools and handle the loop. This is conceptually very similar to MCP’s idea of tools. The difference is that LangChain’s tools are in-process and specific to your application – it’s a coding pattern, not a protocol. For example, if you have a LangChain tool for web search, it’s just a Python function in your app that calls an API. There’s no standard way to share that with another application except by copy-pasting code. MCP, on the other hand, could be seen as LangChain for the network: it allows tools to exist out-of-process, even on different machines, and be reused by any application that speaks the protocol. We can imagine LangChain adding an MCPTool that, given a server address, automatically imports all that server’s tools as LangChain Tool objects. In fact, OpenAI’s new Agents SDK (which likely underpins their plugin system) has already embraced MCP, meaning future “ChatGPT plugins” might simply be MCP servers that any agent framework can use too. So, while LangChain and similar libraries will continue to help developers organize prompts and tool logic (and provide high-level abstractions like “Agent that uses tools until an answer is found”), MCP will ensure that the actual connections to tools are not proprietary.
To sum up the landscape: MCP is positioning itself as the glue that can connect all AI assistants to all services. The future vision for MCP is that it becomes ubiquitous – when you build a new app, you won’t add dozens of custom API calls for your AI, you’ll just connect to the relevant MCP servers. And if a needed server doesn’t exist, you or someone can create it once and share it. We’re already seeing a network effect: Anthropic launched MCP as open-source, companies like OpenAI and Microsoft jumped on board, and thousands of community integrations bloomed in just a few months.
In the broader AI ecosystem, MCP’s rise indicates a shift towards collaboration and standardization. Competing AI labs are cooperating on it, which is somewhat rare and speaks to the practical need for such a protocol. This will likely spur innovation: when every AI can easily use tools and access fresh data, applications will become far more powerful and useful. It also can improve AI safety – when an AI can clarify or verify facts via tools, it’s less likely to hallucinate wrong answers; when it operates through a controlled protocol, monitoring and moderating its actions is easier.
In conclusion, Anthropic’s Model Context Protocol might very well be a game-changer that defines the next era of AI development. By addressing the integration problem head-on with an open standard, MCP enables a future where AI assistants are deeply integrated, context-aware, and collaborative across systems rather than being siloed or reinventing the wheel for each app. As the community rallies around MCP, we can expect smarter and more seamless AI experiences – whether it’s your IDE auto-fixing a bug after consulting your entire codebase, or your personal AI organizing your day by talking to all your apps in one go. Just as USB-C standardized device connectivity, MCP is on track to become the universal interface that lets AI connect with “everything else,” and that’s an exciting development for tech enthusiasts and developers alike.