
How to Build AI Voice Chatbot
Enterprise adoption of voice AI has moved from hype to real-world deployments, thanks to recent breakthroughs in large language models (LLMs), speech technologies, and cloud communications. This comprehensive guide breaks down AI voice implementation into four modules, providing a structured roadmap for enterprise decision-makers. If you would like to learn more about this approach or work with us to implement it for your organization, please reach out to us at hello@gpt-trainer.com.
Table of Contents
- Module 1: RAG-Powered AI Agent Framework
- Module 2: TTS and ASR Integration
- Module 3: Latency and Interaction Optimization
- Module 4: CPaaS Integration
Module 1: RAG-Powered AI Agent Framework
Retrieval-Augmented Generation (RAG) is a key framework that grounds an AI’s responses in specific, up-to-date knowledge. Instead of relying solely on an LLM’s pre-trained knowledge (which can be static or generalized), RAG integrates a live retrieval step before generation. This means your voice agent can fetch facts from internal documents, databases, or even the web, then use that to craft accurate, context-aware answers. The module covers how RAG works, low-code ways to build such agents, multi-agent orchestration, and real enterprise use cases across industries.
What is RAG (Retrieval-Augmented Generation)?
RAG operates in two phases: retrieval and generation. First, the agent retrieves relevant data from knowledge sources (e.g., company intranet, CRM, SOP documents) based on the user’s query. Next, the LLM incorporates that data into its answer. This ensures responses are grounded in facts that are current and domain-specific. Essentially, RAG transforms an LLM from a purely generative model into a question-answering system that cites and uses enterprise knowledge in real time.
How RAG Works: Below is a simplified RAG workflow in an enterprise Q&A context:
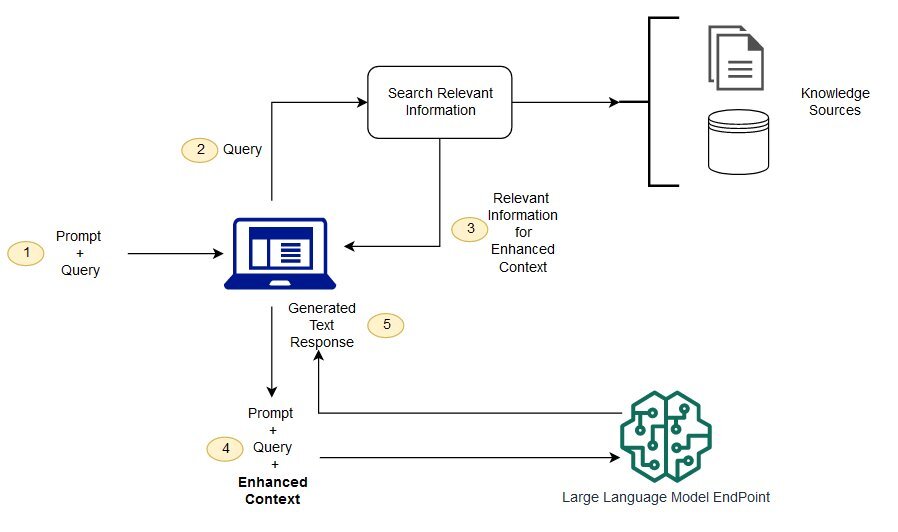
Retrieval-Augmented Generation flow. A user query triggers a similarity search on an indexed knowledge base (vector embeddings). The Q&A orchestrator combines the query with retrieved context and sends it to an LLM (generator) to produce a response
- Knowledge Base & Embeddings: Enterprise data (documents, FAQs, wikis) is broken into chunks and converted into embeddings (numerical vectors). These embeddings capture semantic meaning and are indexed in a vector database.
- Similarity Search: When a voice query comes in, it’s converted to an embedding and matched against the knowledge base to retrieve the most relevant chunks. A common measure of similarity is the cosine distance between embedding vectors.
- Prompt Augmentation: The agent (orchestrator) injects the retrieved text into the LLM’s prompt along with the user’s query (i.e., step 3 in the diagram). This augmented prompt provides the LLM with enterprise-specific context.
- Generation: The LLM generates a response informed by both its training and the provided context. The answer is then returned to the user, often after human review in sensitive settings.
Low-Code / No-Code RAG Chatbot Frameworks
Building a RAG-powered voice agent from scratch can be complex, but emerging platforms offer low-code or no-code solutions. For example, GPT-trainer is a no-code platform that lets you create custom chatbots on your own data. It allows uploading internal documents, automatically chunking and embedding them, and then intelligently feeding relevant pieces to an AI agent using a proprietary RAG framework to enable context-informed generation. GPT-trainer also supports multi-agent chatbots with function-calling capabilities – meaning your chatbot can incorporate multiple specialized AI agents that call external APIs as needed.
Other frameworks and libraries include:
- LangChain (Python/JS) for chaining LLM calls with tools and retrieval steps, often used to implement RAG chatbots quickly. LangChain has integrations for web scraping, vector DBs, and multi-step reasoning.
- LLM orchestration tools like Semantic Kernel or ChromaDB paired with LLM APIs to create tailored agents that can search company data then respond.
- n8n (low-code workflow) which has tutorials for building custom RAG chatbots using visual nodes (e.g., a web scraping node, embedding node, etc.).
- Enterprise SaaS: Several vendors (e.g., Microsoft’s Azure OpenAI with Cognitive Search, AWS’s Bedrock with RAG features) have enterprise-ready solutions to plug in internal search with GPT-like agents.
Multi-Agent Capability and Function-Calling
In complex enterprise workflows, a single AI model may not suffice. Multi-agent systems involve multiple AI agents collaborating or specializing in tasks. For example, one agent might handle general dialogue, another handles domain-specific statistical aggregations, and a third fetches real-time data from an API. Many popular LLMs now support function calling – the ability for the model to output a structured function call when appropriate. This bridges LLM reasoning with real-world operations by letting the AI request an action (like “getCustomerOrderStatus(orderId)”) that your backend then executes.

Module 2: TTS and ASR Integration
At the heart of any voice AI system are two technologies: Text-to-Speech (TTS) for generating spoken output, and Automatic Speech Recognition (ASR) for transcribing user speech. This module compares top TTS/ASR providers and how to integrate them into your chatbot workflow. Key factors include voice quality, customization (persona/tone), API reliability, latency, concurrency (how many parallel conversations can be handled), and fallback mechanisms to ensure uptime.
Top TTS Providers: Voice Quality and Customization
Leading TTS providers as of 2025 include ElevenLabs, Deepgram (TTS), Google Cloud Text-to-Speech, Amazon Polly, Microsoft Azure TTS, and OpenAI’s Whisper (which, though known for ASR, also supports TTS-like completion in some contexts). Each has strengths:
- ElevenLabs: Pioneered ultra-realistic, expressive voices with an emphasis on creativity. It offers thousands of voices in 29 languages and even a Voice Lab to clone or create custom voices. The voice quality is often praised as human-like and emotional, with fine control over style. ElevenLabs provides a web API, Python SDK, and even WebSocket support for streaming. They highlight ~400ms generation times for short text using their Turbo model. Customization: you can define a “persona” voice, adjusting parameters like stability and speaking style. Many game studios and content creators use ElevenLabs for character voices due to this flexibility.
- Deepgram TTS (Aura-2): Deepgram, known for ASR, introduced a high-performance TTS “Aura-2” geared for real-time applications. Voices may be fewer (around 40 English voices as of now) but are professional and clarity-focused. Latency is a differentiator: Deepgram advertises sub-150ms response times and support for thousands of concurrent interactions. They also offer on-prem deployment options (for data-sensitive enterprises) and highlight accuracy in domain-specific terms (e.g., correct pronunciation of product names, medical terms). Deepgram’s platform unifies ASR and TTS, simplifying integration.
- Amazon Polly: AWS’s TTS service with dozens of voices in many languages. Quality is good, though perhaps slightly robotic for some voices compared to ElevenLabs. It does allow some customization via SSML (Speech Synthesis Markup Language) to control pronunciation, emphasis, and pauses. Polly’s strengths are scalability and integration with AWS ecosystem (IAM security, etc.). Latency is typically low, and it supports streamable output.
- Google Cloud TTS: Offers a wide array of voices, including Standard and WaveNet (high quality) voices. Google’s voices are natural and support multiple languages. They have an edge in - multilingual consistency. One standout is their custom voice offering, where you can train a TTS voice on your own audio data (mainly for enterprise tier). Google’s API is robust, with well-documented gRPC/REST interfaces and globally distributed datacenters for low latency.
- Microsoft Azure TTS (Speech Service): Comparable to Google’s, with a large selection of - Neural voices that sound highly natural. Microsoft emphasizes Style and Role options (e.g., newscaster, customer service tone) to fit voice output to scenarios. They also allow custom voice creation via their Custom Neural Voice program. Azure’s documentation is developer-friendly and the service integrates with Azure’s broader Cognitive Services suite for monitoring and logging.
- OpenAI / Whisper: OpenAI’s Whisper is actually an ASR model, but OpenAI’s text completion models (like GPT-4) can produce text that is then fed into any TTS. Recently, OpenAI added a text-to-speech capability in their ChatGPT app with a limited set of voices. While not a public API yet (as of early 2025), this shows the landscape evolving. For enterprises today, one might use Whisper for transcribing audio and then use another TTS for output.
Voice Quality & Naturalness: In terms of pure naturalness, many rank ElevenLabs at the top for its lifelike intonation and emotional range. Deepgram’s voices are highly intelligible and latency-optimized (though perhaps slightly less emotive than ElevenLabs). Google and Azure’s top-tier voices (WaveNet and Neural) are very close to human speech and may excel in certain languages where smaller startups have less coverage. Listening tests often put these providers within a few percentage points of each other in Mean Opinion Score (MOS) evaluations. A recent integration even saw Twilio incorporate ElevenLabs’ voices to enhance their platform, indicating the demand for the most human-like TTS in enterprise voice apps.
Customization Options: For branding, an enterprise might want a unique voice persona (e.g., the voice of their “assistant”). ElevenLabs and Microsoft Custom Neural Voice enable that via training or cloning voices with consent. On a simpler level, most platforms let you adjust speed, pitch, and volume. Some allow you to control speaking style – for instance, Azure might offer <mstts:express-as style="empathetic"> tags for an empathetic tone. These features let enterprises match the voice agent’s tone to the context (cheerful for marketing, calm for support, formal for banking, etc.).
Top ASR Providers: Accuracy, Latency, and Language Support
Automatic Speech Recognition turns the user’s spoken input into text for the AI to understand. The landscape includes Deepgram ASR, Google Speech-to-Text (Cloud ASR), Microsoft Azure Speech, Amazon Transcribe, AssemblyAI, OpenAI Whisper (open-source and API), and others.
Important metrics for ASR are accuracy (word error rate) and latency (especially for real-time use). A 2025 independent benchmark compared major ASR APIs on clean, noisy, accented, and technical speech:
- OpenAI Whisper was a top performer in accuracy across many conditions, especially with clear speech, often achieving the lowest Word Error Rate (WER). It’s robust to noise and non-standard input, likely due to its training on a diverse dataset. Whisper’s model can run via API or on-prem (open-source), but note it doesn’t do streaming via API yet – you’d handle chunking yourself if needed.
- Google Cloud ASR (the “legacy” Google speech API) surprisingly lagged behind in these benchmarks, coming in last in accuracy, especially on accented speech (average WER ~35% on accented test). This aligns with reports that Google might be focusing more on their new “Gemini” LLM-based models rather than improving the older ASR service.
- Google Gemini (speech via LLM) – a newer approach where an LLM that can process audio (Gemini) transcribes speech – showed excellent results on accented and technical speech, even outperforming others in those categories. This signals an emerging trend: using large multimodal models for speech, which might become more accessible in the near future.
- AssemblyAI (a startup ASR provider) also consistently ranked near the top, especially when punctuation/casing is not required. It offers a straightforward API and even features like summarization of transcripts.
- Deepgram ASR: Deepgram often advertises itself as faster and more accurate than others. They provide streaming ASR with latency often under 300ms and strong accuracy in benchmarks. In the independent test, Deepgram was solid (middle of pack in accuracy, similar to AWS Transcribe) – good overall, but not distinctly the top in that particular test. Deepgram does shine in streaming use-cases with stable performance and has the advantage of on-prem deployment for privacy.
- Microsoft Azure Speech: Azure’s accuracy was decent, typically slightly below Whisper and Assembly but above Google’s older model. Azure supports a huge variety of languages and has powerful noise-reduction and diarization (speaker separation) features, useful for call centers.
- AWS Transcribe: Amazon’s service performed well, especially in noisy conditions (it was noted to be resilient to background noise). Accuracy is competitive but perhaps not #1 in any category. AWS is often chosen when an enterprise is heavily on AWS and wants minimal integration friction (IAM roles, VPC endpoints, etc., make it easier to use securely in cloud).
- Deepgram vs. OpenAI Whisper for streaming: If you need real-time transcription (user speaks and AI should start responding immediately), Deepgram or AssemblyAI’s streaming endpoints are useful, as is Google’s streaming API. Whisper can be run in a streaming fashion on your own server, but OpenAI’s hosted API is batch (for now). Tip: Some solutions use a hybrid: quick partial transcriptions via a fast model, then a final alignment with a slower but more accurate model for the transcript (if needed for record-keeping).
Latency Considerations: For a fluid conversation, ASR should ideally transcribe within a second or less after the user speaks. Deepgram cites ~0.3s latency, which is excellent. In practice, network latency and the length of user utterance also matter (transcribing a long paragraph will take longer than a short question). Many systems use streaming ASR with interim results, so the transcription builds word-by-word. This allows the AI to start formulating a response before the user finishes speaking.
Customization: Many ASR APIs allow custom language models or custom vocabularies. For enterprise, this is key if you have unique jargon (product names, technical terms). For instance, you can feed a list of domain-specific terms to AWS Transcribe or Azure to bias recognition. Deepgram and AssemblyAI also let you upload “hints” or even train on your data for better accuracy. Evaluate this if your industry has acronyms or proper nouns the ASR might miss by default.
API Documentation & Support: In an enterprise setting, quality documentation and support are not just nice-to-have – they are essential. Providers like Google, AWS, and Microsoft have extensive docs, SDKs in various languages, and enterprise support plans. ElevenLabs and Deepgram, being newer, have developer-friendly docs (often with example code) and active customer success teams, but it’s worth checking if they offer dedicated support or SLAs for enterprise tiers. Look for features like detailed logging, usage dashboards, and the ability to set up callbacks/webhooks for transcripts.
Integrating TTS and ASR into Workflows
In a voice AI architecture, ASR and TTS act as the input and output layers around your core chatbot logic:
- User speaks into phone or microphone.
- ASR transcribes speech to text. Often this is done via streaming API; some CPaaS (Communications Platform as a Service) providers like Twilio provide a WebSocket that streams audio to an ASR and returns text. The transcribed text goes to the chatbot/LLM (possibly through the RAG framework from Module 1). The AI processes and generates a text response.
- TTS takes the AI’s text response and synthesizes speech audio. The audio is played back to the user over the phone or device speaker.
This loop needs to happen as seamlessly as possible for a natural conversation.
ASR Buffering: A practical detail – sometimes you want to accumulate user speech into a buffer before sending to the chatbot. For example, if using non-streaming LLM API, you might wait until the user finishes speaking (maybe when a few hundred milliseconds of silence is detected) then send the full utterance to the bot. An “ASR buffer” can store interim transcripts. However, to keep things responsive, one can use a hybrid approach: send the interim transcript to the bot, or at least use it to predict user intent early. If the user’s question is long, an advanced system might start searching the knowledge base or prepping an answer in the background.
In voice call scenarios, Twilio’s ConversationRelay (covered later) handles a lot of this: it receives audio, does ASR, and sends your app the final text when the user pauses. In your app, you might maintain a buffer or simply trust the events from your CPaaS provider like Twilio.
After the agent responds, it typically resets state related to speech. Any stored ASR text buffer is cleared for the next user utterance. However, conversational context (the memory of what was said earlier in the call) is usually preserved by the chatbot module. So, you reset only the input buffer, not the entire conversation state.
Error Handling & Fallbacks: What if ASR fails or is not confident? A good design is to handle low-confidence transcripts. If the ASR returns a confidence score below a threshold, the bot might say, “I’m sorry, I didn’t catch that. Could you repeat?” Alternatively, if using multiple ASR providers (some systems double-transcribe with two models for critical tasks), you can fall back to a secondary service if the primary is unresponsive.
For TTS, a potential failure is if the TTS API is down or slow – the system could have a set of pre-recorded fallback phrases (“Our agents are busy, please hold...”) or switch to a backup TTS provider. This is more advanced and usually only needed if uptime is absolutely critical (e.g., 24/7 call centers).
Concurrency Limits: Keep in mind the limits. For instance, ElevenLabs caps concurrent requests by tier (e.g., 10 concurrent on Pro, 15 on Scale plan, unless you have enterprise deal). Deepgram TTS advertises support for thousands of concurrent calls (likely for enterprise license). Ensure your usage volumes either stay within limits or work out a custom plan. If you expect spikes (say 100 users calling at once), test how your TTS/ASR handles it, or orchestrate a queue mechanism.
Monitoring: Finally, integrate logging. Most providers have logging of requests; you can also log transcripts and response times in your app. This helps to identify any recognition errors or speech output issues and continuously improve the voice experience.

Module 3: Latency and Interaction Optimization
Real-time voice interactions demand snappy response times and smooth turn-taking. This module delves into how to optimize latency at various stages and manage the interaction flow, including handling interruptions and ensuring the conversation feels natural.
Dynamic Text Splitting for Responsive TTS
One trick to improve perceived responsiveness is dynamic text splitting. Instead of waiting for the AI to generate a full paragraph and then sending it to TTS, the system can split the AI’s response into smaller chunks (delimited by sentences or clauses) and stream them to the TTS.
Why do this? If the LLM produces a long answer, you don’t want the user to wait in silence. By starting TTS on the first sentence while the LLM is still writing the next ones, the user begins hearing the answer sooner.
For example, suppose the user asks a complex question and the AI will answer with a 5-sentence explanation. Using dynamic chunking:
- The moment the AI outputs sentence 1, you send that to TTS and start speaking it.
- By the time sentence 1 is spoken, sentence 2-3 are ready, etc., creating a continuous stream of audio.
This requires a few capabilities:
- LLM Streaming: Most modern LLM APIs (OpenAI, etc.) support streaming outputs token by token. Your system should capture this stream.
- Sentence Boundary Detection: You can set a delimiter (e.g., period, \n, or special token) to decide when to cut off a chunk. Some simply split on full-stop punctuation plus a short buffer of tokens.
- TTS Streaming: Some TTS services (like certain Google or Azure endpoints, and ElevenLabs via WebSocket) allow streaming synthesis. If not, you can still simulate it by sending multiple requests for chunks.
Keep chunk sizes reasonable – too short and the speech may sound choppy; too long and you lose the benefit. A typical delimiter strategy is splitting on sentence ends or after N characters. You might also preemptively split if the LLM hasn’t finished but has paused (no tokens for, say, 500ms).
Note: Ensure the TTS voices are consistent and can be concatenated without sounding disjointed. Usually using the same voice for all chunks is fine. Minor timing tweaks (like a slight pause at chunk boundaries) can smooth it out.
Streaming and Early Playback of Responses
Related to chunking is the idea of full-duplex audio streaming – the system can listen and speak at the same time. While true full-duplex is hard (we typically alternate turns in conversation), the tech is aiming for overlapping actions:
- Barge-in / interruption: If the user starts talking while the AI is speaking, the system should detect that and possibly pause/stop the TTS.
- Early TTS start: As described, start speaking before the entire text is ready.
Many CPaaS voice frameworks and WebRTC setups support “barging in”. Twilio’s ConversationRelay, for example, handles interruptions: if the caller speaks over the AI voice, Twilio can detect it and notify your app. Your app then should stop the current TTS and listen to the user.
This is critical for a natural feel. Humans often interject or clarify before the other finished. A user should be able to say “actually, I meant X” and the agent should gracefully stop talking and switch to listening.
Implementing Interruptions: One approach:
- Continuously monitor the audio input even while TTS is playing. If energy (volume) is detected above a threshold or the ASR yields new text mid-response, trigger an interruption.
- Use a flag or state machine in your app: e.g., state = Speaking vs Listening. During Speaking, if an interruption triggers, you halt the TTS output (some APIs allow cancellation of speech playback) and change state to Listening.
- You may need to send a stop signal to whatever is generating the audio to avoid overlap. Twilio’s API does that for you if using their native and / or ConversationRelay orchestration.
Session State Management: Voice agent systems often maintain a state machine:
- Idle/Listening: waiting for user speech.
- Processing: user finished, AI is thinking (might play a “hold on” tone if long).
- Speaking: AI is talking (TTS in progress).
Transitioning between these states fluidly is important. For instance, after speaking, go back to Listening for the next user input, and so on. If the conversation ends (user hangs up or says goodbye), exit gracefully.
Infrastructure and Latency Considerations
Where you host your solution and the region of services can impact latency:
- If your users are in Europe and you use a US-east voice server, the round-trip might add noticeable delay. Consider EU-based hosting for EU customers to comply with GDPR and reduce latency. Many providers let you choose region (Azure EU datacenters, AWS EU regions for Polly/Transcribe, etc.).
- GDPR compliance often dictates that audio data (which can be personal data) remains in certain jurisdictions. Plan your architecture so that audio streams and recordings are handled per compliance needs. Some enterprises use on-prem ASR/TTS for this reason (avoiding sending data to cloud). For example, Deepgram’s on-prem deploy or Whisper locally can be used for higher control.
- Server placement: A trade-off: centralize everything in one region for simplicity, or deploy regionally for performance. A global company might spin up ASR in US, EU, APAC regions and direct calls accordingly.
Another factor is telephony latency. If integrating with phone lines, the voice path already has a baseline latency (could be ~100ms to a few hundred ms). You can’t eliminate that, but by optimizing your part (ASR + LLM + TTS processing), you ensure the user doesn’t feel additional lag.
Handling Long Responses and Flow Control
What if the AI’s answer is very long? Perhaps the user asked for a detailed report. Strategies:
- Summarize or shorten by default in voice. Users have limited patience listening to a long monologue. The agent can offer to email the details if the answer is lengthy.
- Allow the user to interrupt with “stop” or “I’ve heard enough” – and train the agent to listen for those cues.
- If a long explanation is necessary, consider chunking it into parts and perhaps inserting prompts like “Would you like me to continue?” every so often.
Voice Agent Persona & Pace: Optimize how the agent speaks:
- People process spoken info slower than written. So even if latency is low, speaking too fast can overwhelm. Ensure the TTS voice’s speed is comfortable (many systems default to a good speed, but can be tuned).
- Use slight pauses between sentences to simulate natural speaking (some TTS do this well automatically).
Example: Interrupting LLM Stream
Let’s illustrate an interruption scenario:
- The user asks a question. The LLM starts formulating a 4-part answer (which might take 10 seconds to fully articulate).
- The agent starts speaking part 1 after 2 seconds (streaming).
- Halfway through part 2, the user realizes it’s not what they need and asks a different question mid-response.
- The system detects the user’s voice (via ASR event) and immediately stops the current TTS.
- The LLM generation might still be ongoing in the background; you would send a cancellation if possible (OpenAI’s API now supports canceling the stream). If not, you just discard the rest.
- The agent transitions to listening mode and then responds to the new question.
This requires careful programming but yields a conversational UX akin to talking to a human agent who can stop and listen when you interject.
State Resynchronization
Sometimes the system may get confused (e.g., lost track whether it should be listening or talking, especially if an interruption occurred at a tricky time). This is where a robust state management and maybe a watchdog helps. For instance, if in Speaking state, and no audio has played for a while (maybe TTS failed silently), the system can timeout and revert to Listening with an apology prompt. Or if in Listening state and user is silent for too long, it can prompt “Are you still there?”.
The voice agent should periodically sync the session state with a central store if distributed, or at least have a clear logic to avoid being stuck. Tools like WebSockets or Twilio’s event stream provide a continuous feed of what’s happening (e.g., “speech started”, “speech ended”) which you can use to keep track.
Example of Latency Trade-off:
One enterprise might choose to host the LLM and vector database on a server in Germany to comply with GDPR for EU callers, even if that means 50ms extra latency for US users. Another might use a U.S. cloud but ensure no personal data is logged, trading regulatory placement for raw speed. These decisions should be made with input from both IT and legal teams, balancing user experience with compliance.

Module 4: CPaaS Integration
Voice AI doesn’t live in a vacuum – it often needs to connect with the telephone network or VOIP systems so users can call a number to reach your AI agent. This is where Communications Platform as a Service (CPaaS) providers come in. CPaaS platforms (like Twilio, Vonage, Plivo, etc.) offer APIs for making and receiving phone calls, managing phone numbers, and handling call audio streams. We will focus on integrating our AI voice bot with CPaaS, using examples like Twilio, and also mention alternatives (Voiceland, Modulus, etc.).
Evaluating CPaaS Providers
Twilio is the most widely known CPaaS, offering a robust Voice API, global phone numbers, and a rich ecosystem. Twilio is often a go-to for ease of setup and documentation. They also are innovating with AI-specific offerings like ConversationRelay which simplifies integrating with LLMs. Twilio provides out-of-the-box scaling and has data centers in multiple regions (important for latency and compliance). The downside can be cost at scale, and some find Twilio’s pricing and limits a bit complex (per-minute charges, etc.). However, Twilio’s enterprise support and reliability are strong.
Other notable CPaaS include Vonage (Nexmo), Plivo, Bandwidth, 8x8, Sinch, Microsoft Teams platform (if internal calls), jambonz (open-source voice gateway for those wanting to self-host telephony).
Key evaluation criteria:
- Voice API Features: Can they stream audio in real-time to your app (WebSocket or SIP)?
- Phone Numbers: Do they provide the phone numbers (DIDs) you need in target countries? And how easy is number management (provisioning via API, configuring call routing)?
- Scalability: Can handle many simultaneous calls. Twilio is known to scale, but it helps to check if others have limits or if you need to request capacity.
- Latency: If their servers are far, it could add delay. Some CPaaS might let you choose regions or have edges near telecom operators.
- Logging & Debugging: Good CPaaS has tools to debug call flows, logs of what caller said (if you enable recording or transcription), etc.
- Pricing: CPaaS usually charges per minute or per API call. Ensure it fits your budget, especially for long calls (if your bot typically engages 5-minute support calls, that cost accumulates).
- Security: Support for TLS, Webhook signature verification, and access control like API keys and tokens.
Connecting Chatbot to Phone Lines
Imagine you have your AI bot logic running (with ASR/TTS integrated). How do you hook it to a phone number?
Twilio example (Generic):
- Buy a number via Twilio (or port an existing one).
- Configure call handling: Typically, you set a webhook URL in Twilio for voice calls. This URL is called when someone dials your number.
- Webhook receives call event: Your server gets details (caller ID, etc.) and should respond with instructions. Twilio uses TwiML (XML) or its Voice API to instruct actions.
- Establish audio stream: Use <Connect> with <Stream> in TwiML to pipe the call’s audio to your WebSocket server. Alternatively, use Twilio’s Conversations or Proxy if that fits (but for raw AI, streaming is common).
- Your middleware receives the audio stream and handles the ASR, passes text to AI, gets response, does TTS.
- Send audio back: Twilio can receive audio to play via the stream connection, or you can command it to play a URL. ConversationRelay handles a lot by letting you just send text back which it converts to speech.
ConversationRelay specifically: Twilio’s ConversationRelay is a new product (beta as of late 2024) that abstracts the ASR/TTS parts. As shown earlier, Twilio can manage the conversion of caller speech to text and your text to speech using providers of your choice. Your app just deals with text over WebSocket – Twilio sends you messages with the transcribed text, and you respond with messages containing the reply text. Twilio then speaks it. This greatly simplifies integration: you don’t have to call ElevenLabs or Deepgram directly; Twilio does it under the hood. However, it can tie you to Twilio’s chosen providers and pricing, so some may prefer manual integration for flexibility.
Other CPaaS integration: If not Twilio, some providers might use SIP (Session Initiation Protocol) to send you the call. Then you’d use a media gateway to get RTP audio, which is more involved. Others like Vonage have their own callbacks and mechanisms (usually similar idea: webhook events for call, and a media stream).
Access Control & Verification: Always secure the webhook endpoints. Use auth tokens or verify signatures to ensure the request is from your CPaaS (e.g., Twilio signs callbacks with X-Twilio-Signature). This prevents malicious actors from hitting your webhook pretending to be calls.
1:1 Mapping of Chatbot Instances to Phone Numbers
For scalability and modularity, it often makes sense to map each phone number to a distinct instance of a chatbot or persona:
- If you have multiple lines (say a support line, a sales line), they might route to different AI behaviors or knowledge bases.
- Or if you have multiple concurrent callers, each needs their own conversation session so conversations don’t mix.
Typically, when a call comes in, your system creates a new chatbot session context (which could be as simple as a unique session ID that you use to store conversation history and state). You tie that session to the call (via call SID or caller ID). When sending/receiving messages on the WebSocket, include the session ID to route to the correct bot logic.
If a user calls again later, do you give them a fresh session or recall their last? That’s a design choice. For personal assistants, remembering past interactions (persistent user profile) can be great. But for, say, a hotline, you might treat each call separately for privacy unless the user authenticates.
Phone number per client instance: Some enterprise solutions assign dedicated numbers to each client’s bot (especially if you’re an AI service provider serving multiple client companies). This isolates the flows and lets you customize for each client. Managing this at scale involves:
- An inventory of numbers (maybe via Twilio API, purchase numbers programmatically).
- A mapping in your database: number X -> triggers bot variant Y with knowledge base Z.
- Onboarding script: when a new client signs up, automatically buy a number and configure it to your webhook with the right parameters. Alternatively, consider establishing an SOP for manual number acquisition.
Standardizing Onboarding and Deployment Workflows
If you plan to deploy many voice bots (e.g., one per branch office, or you’re a vendor offering this to multiple companies), standardize as much as possible:
- Template configuration: Use a base TwiML app or configuration that you can reuse. Twilio allows applying the same code to many numbers.
- Scripts for setup: Write scripts or use Terraform providers for Twilio to auto-provision numbers, set webhook URLs, etc.
- Parameterize: The webhook can include a query param or different path per client, so your app knows which knowledge base or persona to load.
- Admin Portal (if needed): Some CPaaS have an admin UI for managing numbers and SIP domains. Others prefer custom-built ones specific to their needs. Ensure your team knows how to use it or automate it.
CPaaS Admin Portal Customizations
Every established CPaaS has an admin console. Enterprise clients may require:
- Specifying allowed IPs for SIP or webhooks (IP whitelisting for security).
- Configuring voice recording (maybe enable it for compliance).
- Setting up fallback routing: e.g., if your webhook is down, maybe send calls to a human agent or voicemail. Twilio has a fallback URL option in number settings.
- Analytics: use the portal to see call logs, error rates, etc., which can inform improvements.
Also consider telecom regulations: For example, if using phone numbers in different countries, ensure compliance (some countries require local address or identity proof to buy numbers).
Client-Specific Customization
When delivering AI voice solutions to enterprise clients, each might want customizations:
- Voice persona: one client might want a different TTS voice or a unique greeting phrase.
- Knowledge base: each client’s data will differ (Module 1’s retrieval sources).
- Integrations: one might tie into Salesforce, another into HubSpot, requiring different function-calling setups.
- Security: some might insist on all data in their cloud environment. In such cases, maybe you deploy your solution in the client’s VPC or on their premises.
Scalability: Ensure adding a new client doesn’t mean reinventing the wheel each time. It should be more about plugging in new data and config settings into a well-oiled pipeline.
Conclusion
Implementing an AI voice agent in the enterprise is an end-to-end endeavor that spans data, AI models, speech tech, and telephony integration. By breaking it into modules – from the intelligence of RAG-powered frameworks, through voice I/O technology, to latency optimization and telephony integration – enterprises can tackle each piece methodically.
Key takeaways:
- RAG frameworks ensure your AI speaks with knowledge grounded in your enterprise data, and multi-agent architectures with function-calling enable complex workflows beyond basic Q&A.
- TTS/ASR choices determine the voice and ears of your agent; choose providers that fit your quality and scaling needs, and design with fallback and adaptability in mind (e.g., ASR hints, TTS voice tuning).
- Latency optimization is crucial for voice UX. Stream everything you can: start speaking before you’ve finished thinking, and be ready to handle natural human interaction patterns like interruptions.
- CPaaS integration bridges the AI to the real world of phone lines. A reliable CPaaS with real-time audio streaming and robust management features will save you countless hours. Secure your webhooks and plan for scaling new numbers/clients easily.
- Enterprise readiness means achieving compliance standards in regard to reliability, privacy, and security at every step: monitor performance, guard data, and keep the human-in-the-loop for oversight especially during early deployments.
By following this guide, enterprise teams can accelerate building voice AI agents that are accurate, responsive, and seamlessly integrated into their communication infrastructure. The result is a natural, human-like conversational experience for users – whether they’re customers calling a helpline, employees getting HR info from an AI assistant, or partners interacting with a voice-based service – all powered by the convergence of LLM intelligence and advanced voice technology. To learn more about AI voice or how you can partner with GPT-trainer to implement a state-of-the-art production-ready solution, email hello@gpt-trainer.com or schedule a call with our sales team.